记录一下这两天写 python 时遇到的一些性能问题和解决。大部分不能算优化,只是特定 case 下的对性能数字量级的认知。大部分测试基于 python 3.8。
isinstance 和 type is
如果希望检查实例是否 exactly 是某个类型 A,而不包括 A 的子类,用 type(a) is A。
如果希望检查实例是否是 A 或者 A 的子类,用 isinstance(a, A)。
除了语义上的区别,二者的性能也不同,如果检查的类型继承链比较复杂,且结果为 False 时,isinstance 的性能会差很多,否则差不多。
-
在我的 case 中,被检查的类型从
pydantic.BaseModel派生多级。isinstance为 False 时,比type is慢 ~10 倍。from pydantic import BaseModel import timeit class A(BaseModel): a: int pass class B(A): b: int pass class C1(B): c: int pass class C2(B): c: int pass class C3(B): c: int pass c1 = C1(a=1, b=2, c=3) c2 = C2(a=1, b=2, c=3) print("isinstance true ", \ timeit.timeit(lambda: isinstance(c1, C1), number=1000000)) print("type is true ", \ timeit.timeit(lambda: type(c1) is C1, number=1000000)) print("isinstance false", \ timeit.timeit(lambda: isinstance(c1, C2), number=1000000)) print("type is false", \ timeit.timeit(lambda: type(c1) is C2, number=1000000))结果是
isinstance true 0.05928762990515679 type is true 0.08189487305935472 isinstance false 0.6317731359740719 type is false 0.08188665006309748
datetime.strptime
当解析的时间戳格式固定时,手写 datetime 解析比 strptime 更快
def parse_timestamp(time_str: str) -> float:
return datetime.datetime(
int(time_str[:4], 10),
int(time_str[5:7], 10),
int(time_str[8:10], 10),
int(time_str[11:13], 10),
int(time_str[14:16], 10),
int(time_str[17:19], 10),
int(time_str[20:26], 10)
).timestamp()
timestr = "2024-12-06 22:57:00.393023"
print("parse_timestamp", timeit.timeit(lambda: parse_timestamp(timestr), number=1000000))
print("strptime ", timeit.timeit(lambda: datetime.datetime.strptime(timestr, "%Y-%m-%d %H:%M:%S.%f"), number=1000000))
parse_timestamp 1.8856778349727392
strptime 6.808586899889633
如果可以不用 re,那就不用
我需要从字符串中提取出 key1=value key2=value2 ... 这样的 pattern 成一个 dict。
一开始是直接 split(' ') 再 split('='),后来发现某些 value 可能包含空格,图方便就改成了 re.finditer。
但其实这个解析任务是可以不用 re 的,而且手写解析比 re 快很多。具体可以参考代码
KEY_PATTERN = re.compile(r"(\w+)=")
def parse_kv_re(text: str) -> Dict[str, str]:
data = {}
prev_match = None
for match in KEY_PATTERN.finditer(text):
if prev_match:
data[prev_match.group(1)] = text[prev_match.end() : match.start()].strip()
prev_match = match
if prev_match:
data[prev_match.group(1)] = text[prev_match.end() :].strip()
return data
def parse_kv_split(text: str) -> Dict[str, str]:
data = {}
prev_key = None
val = ""
for token in text.split():
if "=" in token:
if prev_key:
data[prev_key] = val
val = ""
prev_key, val = token.split("=", maxsplit=1)
else:
val += " " + token
if prev_key:
data[prev_key] = val
return data
text = 'key1=some_val1 key2=some_val2 key3=some_val3 key4=looooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooong key5={"some": "val", "key": "value", "random": 123}'
assert parse_kv_re(text) == parse_kv_split(text)
print("re ", timeit.timeit(lambda: parse_kv_re(text), number=100000))
print("split", timeit.timeit(lambda: parse_kv_split(text), number=100000))
re 4.418985206983052
split 0.19559685792773962
如果一定要用 re,可以考虑去 regex101 上检查自己 pattern 的性能,例如避免 catastrophic backtracking
另外,还试过把 "=" in token 改成 find,想着这样就可以省掉 split 直接按 index slice,但更慢了,以下 timeit 说明了原因
token = "key2=some_val2"
print("in ", timeit.timeit(lambda: "=" in token, number=1000000))
print("find ", timeit.timeit(lambda: token.find("=") != -1, number=1000000))
index = token.find("=")
print("slice ", timeit.timeit(lambda: [token[:index], token[index + 1 :]], number=1000000))
print("split ", timeit.timeit(lambda: token.split("=", maxsplit=1), number=1000000))
in 0.05515715305227786
find 0.1189718859968707
slice 0.1710334960371256
split 0.15278159803710878
in 实在是太快了,另外 slice 居然也比 split 慢。
当心 gc,尤其是处理大量对象时
python 的 list 被认为是有均摊插入复杂度的,但是当插入的是 object 且数据量很大时,可能会观测到某一次插入操作耗时非常久的情况,也许在代码中会表现为程序莫名其妙地 block 秒级别。我之前写过一篇类似的,gc 与循环引用。
在 SO 上有一个相关的讨论。其回答 中的结论,我在 python 3.8 上 somehow 也能复现,不论是在 list,deque 亦或是 dict 上,例如
import time
import gc
class A:
def __init__(self):
self.x = 1
self.y = 2
self.why = 'no reason'
def time_to_append(size, append_list, item_gen):
t0 = time.time()
for i in range(0, size):
append_list.append(item_gen())
return time.time() - t0
def test():
x = []
count = 10000
for i in range(0,1000):
print(len(x), time_to_append(count, x, lambda: A()))
def test_nogc():
x = []
count = 10000
for i in range(0,1000):
gc.disable()
print(len(x), time_to_append(count, x, lambda: A()))
gc.enable()
test()
test_nogc()
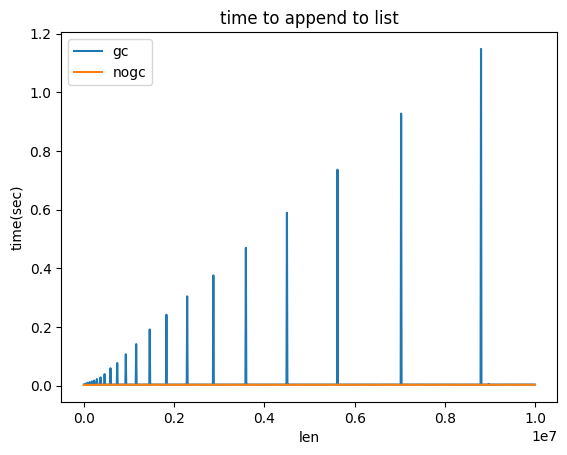
发现这种场景时,可以选择禁用自动 gc 并在合适的时候手动 collect。此外,如果代码不包含任何循环引用,禁用 gc 并且不 collect 应当也是安全的,不会导致内存泄露。可以用 gc 的 DEBUG_LEAK flag 来检查是否有循环引用。
另外,注意这个现象发生的数据量级很大,例如 1e7 个对象时,gc 才会需要 1s。因此如果观测到了这个现象,建议先检查自己的代码,看到底是真的有那么多数据,还是自己忘记了一些资源回收工作导致数据无节制增长了(例如往 dict 里加了 key 但没有删除)。